目录
0 问题
--创建的索引一定能用上吗?为什么?
--employee_id是主键
select employee_id from employees where employee_id = 12345;
--与
select first_name from employees where employee_id = 12345;
--执行的时间会大体相同吗?如果不同为什么?
--创建索引(first_name)
select * from employees where first_name Like 'F%';
--与
select * from employees where first_name Like '%F%'
--哪个会走索引?为什么?
--创建联合索引(employee_id, date_of_birth)
select * from employees where employee_id = 1000 and date_of_birth between '1987-01-01' and '1987-02-01';
--与
select * from employees where date_of_birth between '1987-01-01' and '1987-02-01'and employee_id = 1000;
--对于联合索引,sql条件字段顺序跟索引字段有关系吗?
--如果同时创建联合索引(employee_id, date_of_birth),会走哪个索引?索引字段顺序对执行计划有影响吗?
--创建索引(last_name)
select * from employees where UPPER(last_name) = UPPER('huayu');
--会走索引吗?
--创建索引(first_name, last_name, date_of_birth)
select * from employees where first_name = 'beijing';
select * from employees where first_name = 'beijing' and last_name = 'huayu';
select * from employees where first_name = 'beijing' and last_name = 'huayu' and date_of_birth = '2009-01-01';
select * from employees where last_name = 'huayu' and date_of_birth = '2009-01-01';
-- 或者任意字段的索引组合,都会走索引吗?有什么不同?
1 索引剖析
重要概念
堆(Heap)
存储数据库表数据的地方,最小的存储单位是页,或者叫block,一般是8kb。表的数据会存储在一个个页中,物理上来讲是不连续的。每一个页的头部有pointer,指向本页的中的具体数据
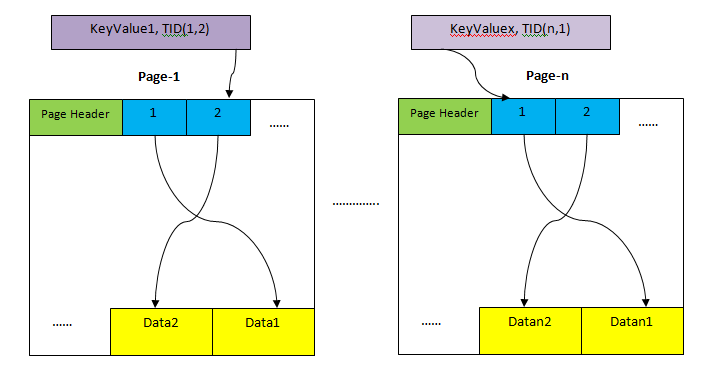
索引存储(Index Storage)
索引是独立的数据,但是只存储关键数据(索引字段),也是用页的形式存储,一个索引数据是有序的
元组标识(TID, Tuple Identifier)
TID是一个6byte的数值,前4byte代表数据页numer,后2byte代表数据在该页中的offset。一个TID就可以唯一标识一个元组的Heap存储位置
元组的概念和数据库中row的概念是一致的,前者是一种抽象,后者是一种具体。就像relation和table一样
select ctid from employees where employee_id = 10000;
select ctid from employees where employee_id < 10000;
索引数据结构B-Tree
索引的数据结构有很多:B-Tree,Hash,GIN,GiST…
索引是数据库独立管理的数据,用来避免出现只需要查询一小部分数据但是却要读取整个table的情况,实质上是无序物理数据的一个逻辑上的有序表示
为什么物理数据从存储不能是有序的?
怎么样创建索引:
- 关键数据拿出来排序,存放在数据库页(页是数据库最小的使用单元)
- 建立一个数据结构让索引数据有序
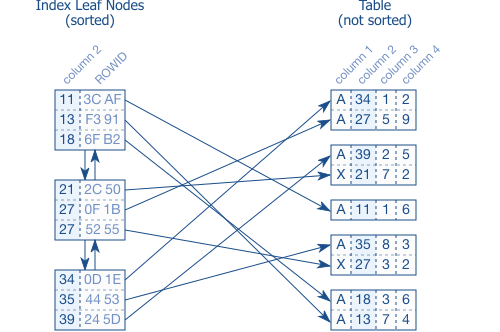
Index Leaf Node
双向链表的数据结构,将物理上无序的索引数据页建立双向链表数据结构,便于插入和删除node节点,以及正向和反向遍历index数据。
Index数据和table数据存储的异同:二者页与页之间都是没有关联的,无序的。
table数据页内部tuple也是无序的,而Index数据页内部tuple是有序的。整个Index数据的有序是通过Index页内数据的有序和Index Leaf Node双向链表数据结构实现的
索引数据页内tuple排序 + Index Leaf Node这样的数据结构相对于Heap数据排序有什么优点呢?
这个有序的Index Leaf Node是否能够快速的定位某个一数据呢?
Balance Tree
B-Tree是在Index Leaf Node之上建立的平衡树,用来能够快速定位数据所在的页
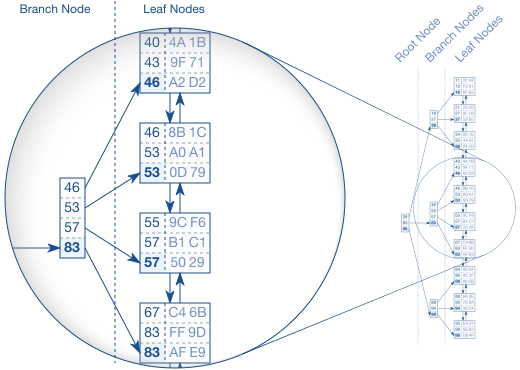
实质上,为了能够快速的定位数据,数据库做了三个方面的事情:
- 创建索引数据时,索引数据页内的tuple是有序的
- 基于索引数据页创建Index Leaf Node双向链表数据结构,确保逻辑上整个索引数据有序
- 基于Index Leaf Node数据建立Balance Tree,确保能够快速定位数据在那个索引页
走索引sql执行阶段
1. 遍历树(B-Tree Traverse)
从Root Node开始,按照平衡树的搜索算法,直到找到叶子节点页
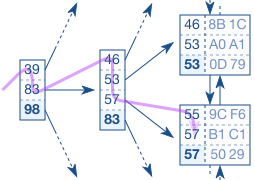
2. 搜索叶子节点(Index leaf node search)
找到对应叶子节点页后,在页中搜索数据
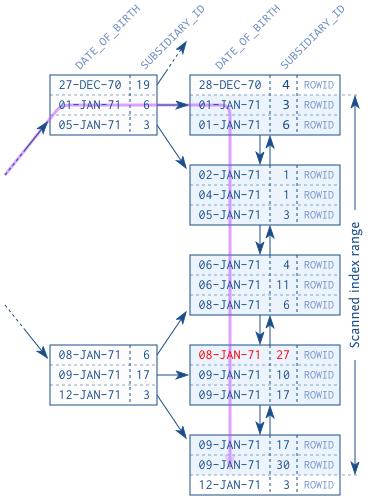
对于非unique的索引,tree traverse之后的index leaf node搜索可能结果很多,这样就可以能跨页来搜索数据,相对于tree traverse来说,这一步的成本可能没有上界
3. 获取数据(Access data from table by rowid)
根据得到的index数据,从Heap中load数据
索引对性能可能的影响
- 遍历树。由于平衡树的数据结构,这部分时间是有上限的,因为数的成长是平衡的,先横向增长再长高
- 搜索叶子节点。这部分时间是有一定上限的(相比较整表扫描来说),对于唯一索引用等于来查询的话,最多在一个页内搜索,成本可以忽略。如果是条件搜索或者非唯一索引,可能在这一步要跨多个index页数据搜索,会有一定的成本
- 获取数据。这部分是索引性能的关键影响,如果查询出来的索引数据结果很大,那么就要频繁从Heap中load数据,每一次load都是Random Access I/O(根据TID从对应数据页中获取数据),成本相比较sequence I/O要大不少
从2和3成本的角度分析,如果索引结果集相对较大,但有不至于走全表扫描的成本,在索引层次有没有什么办法处理来减小查询成本?
2 执行计划
- cost-based
- rule-based
rule-based是预先设置好的规则,按照规则生成执行计划。这种一般现在很少用
code-base以成本为依据,选择执行计划成本最小的最为最终的执行方案
优化器(Optimizer)在进行执行计划成本计算(explain)的时候,并没有真正的执行,依靠什么来计算各执行计划的成本呢?
explain vs explain analyze区别:explain只是基于base规则生成执行计划;而explain analyze实际上执行了这个Query
Mysql数据库工作过程
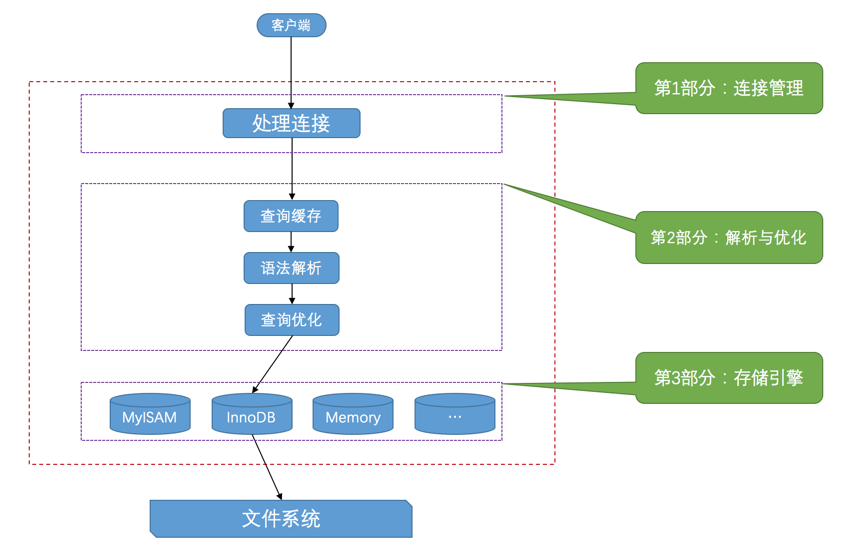
- 连接管理。服务端处理客户端进程连接相关内容
- 解析与优化
- 查询缓存。同样的sql语句会走缓存数据
- 语法解析
- 查询优化。执行计划的生成
- 存储引擎。数据存储和获取通过这个模块的接口
统计信息对执行计划决策的影响
统计信息主要存储在表:pg_class和pg_statistics中。
pg_class存储表、索引等创建需要的数据库页数、表行数等信息
SELECT reltuples, relpages FROM pg_class where relname = 'employees_1h';
1e+06 142858
VACUUM employees_1h;
这里的信息是estimation,新创建一个表数据库estimation需要10个数据库页和1000行数据,当插入或者删除数据时,这些信息不回自动更新,需要用命令:VACUUM ${TABLE_NAME}
pg_statistics存储列相关的数据:null值的多少、重复数据的多少、最长出现的数据等等
SELECT attname, null_frac, avg_width, n_distinct, most_common_vals, most_common_freqs, histogram_bounds, correlation FROM pg_stats where tablename = 'employees_1h';
同样,表字段的统计信息也不会在数据插入或者删除的时候自动更新,需要用命令:ANALYZE ${TABLE_NAME}
会看执行计划
数据库优化器最终会生成一个树状结构的执行计划,执行计划的叶子节点称为表扫描节点(table scan node),这个节点标识用什么方式扫描表(是否有索引,什么算法等),Postgre支持的表扫描:
- 顺序扫描(Sequential Scan)
- 索引扫描(Index Scan)
- 只索引扫描(Index Only Scan)
- 位图扫描(Bitmap Scan)
- 元组扫描(TID Scan)
Sequence Scan
explain analyze
select * from employees where employee_id > 1;
Seq Scan on employees (cost=0.00..259361.00 rows=1000000 width=1028) (actual time=0.040..4094.349 rows=999999 loops=1)
Filter: (employee_id > '1'::numeric)
Rows Removed by Filter: 1
Planning time: 34.928 ms
Execution time: 4151.501 ms
顺序扫描一般有两种情况:
- where条件的字段没有索引
- where条件字段有索引,但是走索引的成本更高,执行计划也会选择全表扫描
顺序扫描发生的是sequence I/O,相对于Random Access I/O,有什么优点?
为什么走索引的成本有时会比走全表扫描要慢?可以先看看Index Scan有哪些问题,再回来
Index Scan
explain analyze
select * from employees where employee_id = 1;
Index Scan using employees_pk on employees (cost=0.42..8.44 rows=1 width=1028) (actual time=0.025..0.026 rows=1 loops=1)
Index Cond: (employee_id = '1'::numeric)
Planning time: 0.333 ms
Execution time: 0.072 ms
存在的问题:Index Scan获取Index Value(TID)之后会从Heap区域获取数据,也就是从某个数据库页的offset Tuple上获取数据,这是一个Random I/O Access的过程,相比较Sequence I/O是比较慢的。所以,如果大量索引扫描Index Value返回的话,性能上可能受较大影响
解释上面问题:为什么走索引的成本有时会比走全表扫描要慢?
Index Scan可以看成走了两个步骤:
- B-Tree Traverse And 和 Leaf Node Search
- Access data from table by rowid
Only Index Scan
explain analyze
select employee_id from employees where employee_id = 1;
Index Only Scan using employees_pk on employees (cost=0.42..8.44 rows=1 width=6) (actual time=12.058..12.061 rows=1 loops=1)
Index Cond: (employee_id = '1'::numeric)
Heap Fetches: 1
Planning time: 0.133 ms
Execution time: 12.101 ms
Only Index Scan可以看成走了两个步骤:
- B-Tree Traverse
- Index Leaf Node Search
Bitmap Scan
如果索引结果集相对较大,但有不至于走全表扫描的成本,在索引层次有没有什么办法处理来减小查询成本?
explain analyze
select * from employees where employee_id > 900000;
Bitmap Heap Scan on employees (cost=3073.28..195346.23 rows=103336 width=1028) (actual time=27.274..77.604 rows=100000 loops=1)
Recheck Cond: (employee_id > '900000'::numeric)
Heap Blocks: exact=23137
-> Bitmap Index Scan on employees_pk (cost=0.00..3047.45 rows=103336 width=0) (actual time=22.243..22.243 rows=100000 loops=1)
Index Cond: (employee_id > '900000'::numeric)
Planning time: 0.194 ms
Execution time: 83.702 ms
Bitmap Scan主要是为了解决Index San有大量的Random I/O Access但是成本又不至于要全表扫描的情况
Bitmap Scan可以看成走了四个步骤:
- B-Tree Traverse
- Index leaf Node Search
- 根据得到的Index value创建一个bitmap(可以理解为一个hashmap,每一个entry都是目标tuple组成的list)数据结构
- 基于bit map数据进行数据获取
Bit map的关键作用在于,将分散在不同数据页的数据找出来,避免对同一个数据页的多次Random I/O Access
TID Scan
select ctid from employees where employee_id = 10000;
(143816,2)
EXPLAIN ANALYZE
select * from employees where ctid = '(143816,2)'
Tid Scan on employees (cost=0.00..4.01 rows=1 width=1028) (actual time=245.242..245.244 rows=1 loops=1)
TID Cond: (ctid = '(143816,2)'::tid)
Planning time: 0.169 ms
Execution time: 245.297 ms
可以在表中直接查出来某一行数据的TID,TID作为条件查询时,走元组扫描方法
3 Where语句与索引
等于/不等于
单字段索引
主键默认会创建索引,并且是唯一索引
当待索引字段没有重复值时,可以创建唯一索引,反之则不能
对于唯一索引来说,其where等于索引字段的性能只和树的高度有关,而非唯一索引就要考虑到Index Leaf Node Search这一相对成本较大的操作
不等于条件不会走索引
联合索引
sql中书写字段的顺序和是否走索引或者走哪个索引没有关系,实质上优化器会尝试调整顺序,预估多种方案来决定走哪个索引或者是否走索引
创建索引时字段的顺序对执行计划有很大的影响
explain analyze
select * from employees where first_name = 'huayu' and date_of_birth between '1978-10-01' and '1998-12-01'
--创建索引(date_of_birth, first_name)
Index Scan using "i_dateOfBirth_firstName" on employees (cost=0.42..5669.83 rows=6 width=1028) (actual time=0.771..15.770 rows=29 loops=1)
Index Cond: ((date_of_birth >= '1978-10-01'::date) AND (date_of_birth <= '1998-12-01'::date) AND ((first_name)::text = 'huayu'::text))
Planning time: 0.290 ms
Execution time: 15.837 ms
--创建索引(first_name, date_of_birth)
Index Scan using "i_firstName_dateOfBirth" on employees (cost=0.42..18.30 rows=6 width=1028) (actual time=0.321..0.377 rows=29 loops=1)
Index Cond: (((first_name)::text = 'huayu'::text) AND (date_of_birth >= '1978-10-01'::date) AND (date_of_birth <= '1998-12-01'::date))
Planning time: 7.725 ms
Execution time: 0.428 ms
索引的过程
.png)
postgre官方文档对于联合索引说明,任意的一个索引子集查询原则上都能够走索引,但是left most索引最有效
比如a,b,c三个字段作为索引字段,使用使用where a = ? 或者whre a = ? , b = ? 或者where a = ?, b = ?, c = ? 都是很有效率的索引。实际上使用where a = ? and c = ?也能够走索引,只是效率没有left most组合高
自定义函数
explain analyze
select * from employees where UPPER(first_name) = 'FMZ'
--创建索引(first_name)
Gather (cost=1000.00..254611.00 rows=5000 width=1028) (actual time=271.720..915.371 rows=727937 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on employees (cost=0.00..253111.00 rows=2083 width=1028) (actual time=120.553..615.495 rows=242646 loops=3)
Filter: (upper((first_name)::text) = 'FMZ'::text)
Rows Removed by Filter: 90688
Planning time: 0.547 ms
Execution time: 952.985 ms
--创建索引(UPPER(first_name))
Bitmap Heap Scan on employees (cost=95.17..17867.35 rows=5000 width=1028) (actual time=152.854..465.286 rows=727937 loops=1)
Recheck Cond: (upper((first_name)::text) = 'FMZ'::text)
Rows Removed by Index Recheck: 19
Heap Blocks: exact=51268 lossy=52742
-> Bitmap Index Scan on "i_UPPER_firstName" (cost=0.00..93.92 rows=5000 width=0) (actual time=140.239..140.239 rows=727937 loops=1)
Index Cond: (upper((first_name)::text) = 'FMZ'::text)
Planning time: 0.642 ms
Execution time: 491.250 ms
自定义函数一定是一个确定的函数,也就是说对于同样的输入,一定会返回同样的输出。像年龄这种getNl(Date)自定义函数,如果函数中使用了now()当前系统时间,这样的函数索引就不正确。因为函数的返回值会随着时间的变化,不是一个确定性的函数
区间
大于小于/Between、Like/全文搜索
大于小于、Between都可以走索引
对于Like,如果是select * from table where a like 'TERM%OTHER'那么解析器会将之转化为大于小于,走索引;如果是select * from table where a like '%TERM%'全文搜索,就不走索引
explain analyze
select * from employees where first_name like 'A%D';
Index Scan using i_first_name on employees (cost=0.42..1603.35 rows=26 width=1028) (actual time=12.244..12.244 rows=0 loops=1)
Index Cond: (((first_name)::text >= 'A'::text) AND ((first_name)::text < 'B'::text))
Filter: ((first_name)::text ~~ 'A%D'::text)
Rows Removed by Filter: 5596
Planning time: 0.707 ms
Execution time: 12.288 ms
explain analyze
select * from employees where first_name like '%A%D';
Gather (cost=1000.00..253071.93 rows=26 width=1028) (actual time=633.371..633.371 rows=0 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on employees (cost=0.00..252069.33 rows=11 width=1028) (actual time=626.580..626.580 rows=0 loops=3)
Filter: ((first_name)::text ~~ '%A%D'::text)
Rows Removed by Filter: 333333
Planning time: 0.231 ms
Execution time: 641.282 ms
部分索引
在Postgresql中所谓的部分索引(partial index)指的是只针对某些特定的行来建索引
一个用例是:假设一个表中有mobile字段,mobile字段可以为空值,如果直接对mobile建立唯一索引,那么肯定建议不了,有null值是重复的。这样就可以用partial index把nulll值给过滤掉建立索引,例如:create index table(mobile) where mobile is not null
另一个场景是:消息表中有processed字段、userid字段。如果想查询未处理消息是这样的,select * from t where processed = 'N' and userid = ?。我们可以通过建一个联合索引的方法加快查询,但是这个索引中有大量的消息是processed=’Y’,如果只是相对未处理的消息加索引,可以这样:create index t(userid) where processed = 'N'
4. 联表查询JOIN与索引
两表或者多表联表查询的时候改变了原来以表为单位各个列之间的关系,使得不同的表的列可以出现再同一个关系结果中。
JOIN的方式有三种:Nested Loop Join、Hash Join和Sorted Merge Join。
无论用什么join算法,有一点是肯定的,就是每次只处理两个表的join,然后基于结果集再join其他表。这样join的顺序就很重要,如果两个表join的结果数据集小,这样再和其他表join的时候,中间过程的笛卡尔积就会少。优化器也会计算各种join order的组合来判断出一个最优的顺序。
4. Nested Loop Join
#select * from A JOIN B on A.ID < B.ID
For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)
4.2 Hash Join
hash join是为了解决nested loop join的缺陷:在inner query中有很多BTree Traverse。Hash JOIN选择一个候选表hash到内存中,和另外一个表join是能快速的获取数据。因此如果只给join表的关联字段加索引在Hash join算法中提高性能。但是,如果where语句中有独立的字段顾虑时,给这个字段加索引是能够提高性能的。
hash join的步骤:
- 全表扫描(或者有条件过滤)一个表到hashtable中,关联条件作为hash key
- 全表扫描另外一个表,同时过滤
- 第二个结果集数据从第一个结果集中load数据
This algorithm works in two phases:
- Build Phase: A Hash table is built using the inner relation records. The hash key is calculated based on the join clause key.
- Probe Phase: An outer relation record is hashed based on the join clause key to find matching entry in the hash table.
kkkk
#select * from A JOIN B on A.ID = B.ID
#Build Phase
For each tuple r in inner relation B
Insert r into hash table HashTab with key r.ID
#Probe Phase
For each tuple s in outer relation A
For each tuple r in bucker HashTab[s.ID]
If (s.ID = r.ID)
Emit output tuple (r,s)
4.3 Sorted Merge Join
#select * from A JOIN B on A.ID = B.ID,用这个前提是A、B都是有序的,并且join条件是等于的情况
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;
参考:
